
arXiv: https://arxiv.org/pdf/2604.09687
The Blind Spot of the "Reasoning" Race
In the large models era, the quest for Artificial General Intelligence has largely focused on reasoning capability to follow complex instructions and solve abstract problems. However, human-level intelligence also requires the capacity to faithfully capture and process every visual detail within a structured environment.
Current evaluation benchmarks often focus on high-level reasoning or "gist" understanding, which can obscure a fundamental failure: most Vision-Language Models (VLMs) struggle with an exhaustive read-out of visual information. In domains like automated accounting, GUI navigation, or medical imaging, "getting the gist" isn't enough—missing a single cell or a local detail can lead to catastrophic system errors.
Today, we introduce Grid2Matrix (G2M), a diagnostic benchmark designed to measure the limits of visual fidelity and expose the representation-to-expression gap in today's leading architectures.
Grid2Matrix: A Stress Test for Exhaustive Read-out
G2M removes semantic "shortcuts" to isolate a model's ability to preserve fine-grained visual structure. The task is deceptively simple:
- The model is shown with a synthetic color grid.
- It is given a color-to-number mapping dictionary.
- It must output the exact corresponding matrix.
By varying grid size and color density, G2M allows us to increase visual complexity while minimizing semantic confounds, providing a clean window into how well a model can truly capture every detail.
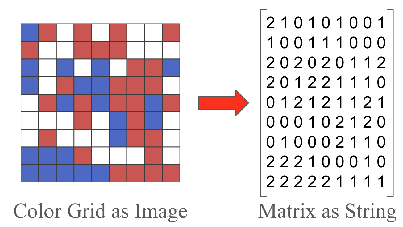 Figure 1: The G2M Task: convert visual color grids into numerical matrices
Figure 1: The G2M Task: convert visual color grids into numerical matrices
The Findings
Our evaluation of frontier models shows that even the most advanced systems fail at this foundational level of visual processing:
-
The Problem of Early Collapse: VLMs exhibit a sharp "early collapse" rather than a gradual degradation. In zero-shot evaluations, models often fail on surprisingly small grids, even when the information is theoretically within the vision encoder's resolution.
-
The Information-Expression Gap: We find that vision encoders preserve substantially more information than is ultimately expressed in the model's textual output. This gap, which we term Digital Agnosia, suggests that the bottleneck lies not just in "seeing," but in the model's ability to faithfully translate those internal representations into language.
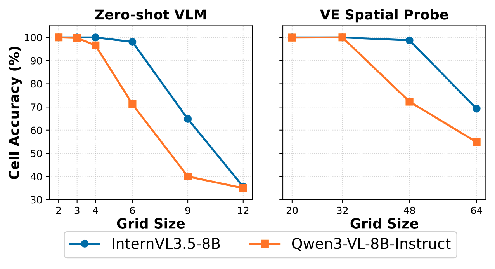 Figure 2: The Performance Cliff: End-to-end model accuracy (orange) collapses on small grids, while the internal vision encoder (blue) still retains the necessary information.
Figure 2: The Performance Cliff: End-to-end model accuracy (orange) collapses on small grids, while the internal vision encoder (blue) still retains the necessary information. -
The Problem of Structured Spatial Bias: Failure modes are not random but highly structured. Errors often depend on the precise alignment between grid cells and the spatial patches used by the vision encoder, leading to predictable hallucinations or omissions.
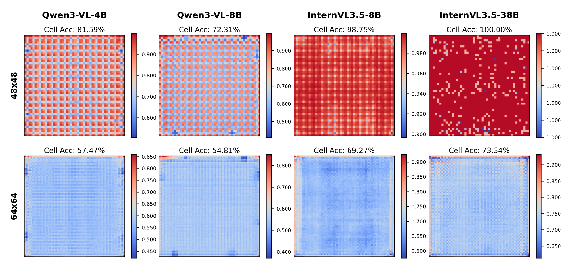 Figure 3: Visualizing Digital Agnosia: error map over testset reveal structured blind spots that persist even after the model has undergone multimodal alignment.
Figure 3: Visualizing Digital Agnosia: error map over testset reveal structured blind spots that persist even after the model has undergone multimodal alignment.
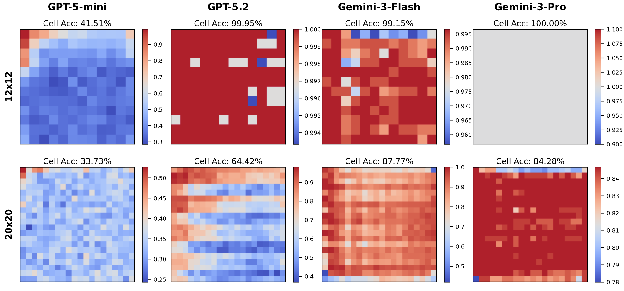 Figure 4: Scaling on proprietary models on 12 × 12 and 20 × 20 grids
Figure 4: Scaling on proprietary models on 12 × 12 and 20 × 20 grids
Significance & Outlook
Why focus so intensely on a simple color grid? Because if a vision model fails to capture such a fundamental dense structure, it cannot be expected to faithfully process complex tables and GUI layouts in real-world enterprise applications. Crucially, once these spatial biases are baked into the vision encoder during pre-training, they become a permanent bottleneck that is exceptionally difficult to rectify through downstream fine-tuning.
We leverage G2M as a high-value diagnostic instrument to identify these early-stage limitations. Our current work is focused on understanding where today's models fall short, using these insights as a foundation for future development. By precisely mapping the limits of visual fidelity, we are exploring new pathways to curate intent-driven, high-quality datasets—building the groundwork for a next-generation data engine that helps AI truly "see" the world's structure.