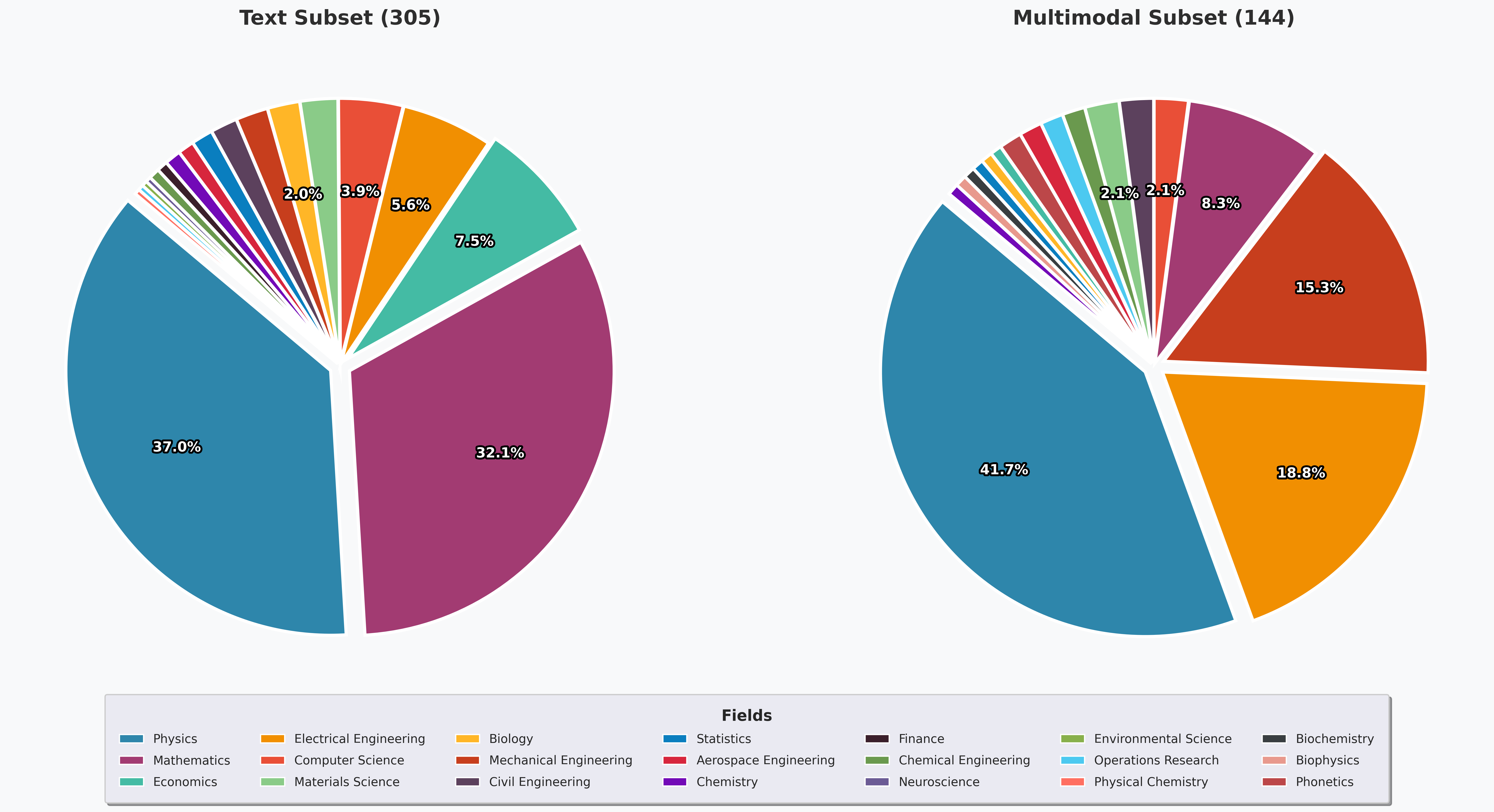
CFE-Bench is a cross-disciplinary STEM reasoning benchmark consisting of a text-only split (305 questions) and a multimodal split (144 questions). The text-only subset primarily covers Physics and Mathematics, with additional problems in Economics, Electrical Engineering, and Computer Science. The multimodal subset emphasizes Physics and multiple engineering domains, including Electrical and Mechanical Engineering, alongside a diverse tail of other STEM fields.
Evaluating STEM solutions is notoriously brittle due to algebraic variations and verbose reasoning. To reduce false positives from directly comparing long-form model responses with full reference solutions, we introduce variable based evaluation, denoted as Short-to-Short (S2S).
| Setting | Acc (%) | AUC | P | R | F1 | FN | FP |
|---|---|---|---|---|---|---|---|
| S2S | 98.03 ± 0.77 | 0.98 ± 0.01 | 0.98 ± 0.01 | 0.98 ± 0.01 | 0.98 ± 0.01 | 4.75 ± 1.79 | 1.25 ± 0.83 |
| L2S | 96.72 ± 0.40 | 0.96 ± 0.01 | 0.97 ± 0.00 | 0.97 ± 0.00 | 0.97 ± 0.00 | 1.50 ± 0.50 | 8.50 ± 1.50 |
| L2L | 89.67 ± 0.75 | 0.89 ± 0.01 | 0.90 ± 0.01 | 0.90 ± 0.01 | 0.90 ± 0.01 | 11.00 ± 2.55 | 20.50 ± 1.12 |
Table 1: Performance summary across evaluation settings. S2S achieves the highest accuracy and the lowest False Positive (FP) rate.
Our S2S framework anchors evaluation to expert-annotated ground-truth variables: \( V_{\mathrm{gt}}=\{(v_i,d_i,x_i,t_i)\} \). By extracting specific predicted values \( \hat{x}_i \) and comparing them against these targets, we eliminate the ambiguity of holistic narrative matching. As shown above, S2S yields the strongest overall performance and substantially reduces false positives relative to L2L, providing a more conservative and discriminative measure of model capability.
We evaluate a broad set of state-of-the-art models using our variable-based protocol with two metrics: Variable Accuracy (average fraction of correct variables per question) and Question Accuracy (all variables must be correct). Across both subsets, Question Accuracy is substantially lower, revealing that models often solve some components while failing others.
| Text + Multimodal (449) | |||
|---|---|---|---|
| Model | Variable Acc. | Question Acc. | |
| Open | Llama-4-Maverick | 21.82% | 16.48% |
| Qwen3.5-397B | 53.60% | 47.44% | |
| Prop. | Qwen3.5-plus | 53.60% | 47.00% |
| Claude-Opus-4.6 | 54.15% | 47.66% | |
| Grok-4-0709 | 47.78% | 41.65% | |
| Grok-4.1-fast-reasoning | 44.18% | 38.08% | |
| GPT-5.2 | 55.80% | 48.78% | |
| Gemini-3-Flash-Preview | 62.90% | 55.46% | |
| Gemini-3-Pro-Preview | 62.70% | 55.01% | |
| Gemini-3.1-Pro-Preview | 66.04% | 59.69% | |
Open-weights Proprietary | Bold underline = best in group, underline = second-best in group.
| Text Subset (305) | |||
|---|---|---|---|
| Model | Variable Acc. | Question Acc. | |
| Open | Gemma-3-27B-it | 13.79% | 9.84% |
| Ministral-3-14B-Reasoning | 17.92% | 13.11% | |
| Llama-4-Maverick | 24.53% | 19.67% | |
| GPT-oss-120b | 41.15% | 34.43% | |
| Qwen3-235B-Instruct | 37.41% | 32.46% | |
| Qwen3-235B-Thinking | 39.31% | 32.79% | |
| Qwen3.5-397B | 54.12% | 48.52% | |
| MiniMax-M2.1 | 33.44% | 27.54% | |
| MiniMax-M2.5 | 34.46% | 28.52% | |
| Kimi-K2-Instruct | 24.62% | 19.02% | |
| Kimi-K2-Thinking | 46.28% | 39.02% | |
| Kimi-K2.5 | 51.32% | 43.93% | |
| GLM-4.7 | 44.79% | 39.02% | |
| GLM-5 | 47.24% | 41.64% | |
| DeepSeek V3.2 (chat) | 48.08% | 41.64% | |
| DeepSeek V3.2 (reasoner) | 50.07% | 43.28% | |
| Prop. | Qwen3.5-plus | 54.43% | 48.20% |
| Claude-Sonnet-4.5 | 36.74% | 29.51% | |
| Claude-Opus-4.5 | 49.03% | 41.97% | |
| Claude-Opus-4.6 | 58.95% | 52.79% | |
| Grok-4-0709 | 53.24% | 47.54% | |
| Grok-4.1-fast-reasoning | 49.58% | 43.61% | |
| GPT-5.2 | 57.99% | 51.15% | |
| Gemini-3-Flash-Preview | 66.02% | 58.69% | |
| Gemini-3-Pro-Preview | 65.29% | 58.03% | |
| Gemini-3.1-Pro-Preview | 70.66% | 64.92% | |
| Multimodal Subset (144) | |||
|---|---|---|---|
| Model | Variable Acc. | Question Acc. | |
| Open | Gemma-3-27B-it | 6.83% | 2.78% |
| Llama-4-Maverick | 16.09% | 9.72% | |
| InternVL3-78B-Instruct | 6.52% | 2.78% | |
| InternVL3.5-GPT-OSS-20B | 3.81% | 2.08% | |
| InternVL3-5-38B | 10.23% | 5.56% | |
| InternVL3.5-241B-A28B | 10.76% | 4.86% | |
| Qwen3-VL-32B-Instruct | 18.99% | 10.42% | |
| Qwen3.5-397B | 52.50% | 45.14% | |
| GLM-4.6v | 15.15% | 7.64% | |
| Prop. | Qvq-max | 9.58% | 5.56% |
| Qwen3.5-plus | 52.32% | 44.44% | |
| Claude-Sonnet-4.5 | 27.04% | 18.75% | |
| Claude-Opus-4.5 | 38.50% | 30.56% | |
| Claude-Opus-4.6 | 43.99% | 36.81% | |
| Grok-4-0709 | 36.23% | 29.17% | |
| Grok-4.1-fast-reasoning | 32.73% | 26.39% | |
| GPT-5.2 | 51.17% | 43.75% | |
| Gemini-3-Flash | 56.31% | 48.61% | |
| Gemini-3-Pro-Preview | 57.22% | 48.61% | |
| Gemini-3.1-Pro-Preview | 56.26% | 48.61% | |
Open-weights models Proprietary models | Bold underline = best in group, underline = second-best in group.
On the text-only split, Gemini-3.1-Pro-Preview leads with 64.92% question accuracy, followed by GPT-5.2 (51.15%) and Claude-Opus-4.6 (52.79%). Among open-weight models, Qwen3.5-397B tops at 48.52%, with Kimi-K2.5 (43.93%) close behind.
The multimodal split is harder across the board. The Gemini-3 family leads (48.61% Q. Acc.), while Qwen3.5 reaches 45.14%, narrowing the open-proprietary gap. However, most other open-weight vision-language models remain at or below 10%, revealing a sharp capability cliff outside the top tier.
To understand why even strong models remain far from reliable, we focus on Gemini-3-Flash and analyze only the instances it fails to solve end-to-end. Our diagnosis is organized around three questions: (Q1) Does the model fail due to missing reasoning/knowledge at the atomic level? (Q2) Is failure primarily driven by multi-step reasoning and error accumulation? (Q3) Does providing a single critical reasoning unit (e.g., a key fact or transformation) substantially increase the probability of reaching the correct final answer? We also assess reasoning efficiency by comparing the length of model-generated reasoning flows to the ground truth.
We decompose each reference solution into an ordered sequence of verifiable reasoning units \( R = [u_1, u_2, \dots, u_n] \), where each unit \( u_i = \langle u_i^q, u_i^a \rangle \) pairs a sub-question (isolating a single step such as retrieving a fact, applying a formula, or performing a derivation) with its verifiable target answer. This representation enables step-wise evaluation, allowing us to probe whether models fail due to atomic deficits (inability to execute a single unit) or compositional deficits (inability to chain otherwise-solvable units), and to define controlled interventions that condition model outputs on partial reasoning states. We instantiate \( R \) via a two-stage pipeline: first, a judge model (GPT-mini) proposes a candidate decomposition into units; then, human annotators verify that each sub-question is unambiguous and each target answer is objectively checkable. The table below illustrates a representative example.
Question: Short circuited parallel plate electrodes of area \( A \) enclose a lossy dielectric of thickness \( s \) with dielectric permittivity \( \varepsilon \) and ohmic conductivity \( \sigma \). The lossy dielectric at time \( t=0 \) has a uniformly distributed free volume charge density \( \rho_0 \). Neglect fringing field effects. What is the current \( i(t) \) flowing through the short circuit?
| Step | Question \( u_i^q \) | Answer \( u_i^a \) |
|---|---|---|
| \( u_1 \) | Write the expression for the total current density in a lossy dielectric in terms of \( \sigma \), \( \varepsilon \), and \( E_x \) at the electrode (\( x = s \)). | \( \displaystyle \frac{i(t)}{A} = \sigma E_x\big|_{x=s} + \varepsilon \frac{\partial E_x}{\partial t}\bigg|_{x=s} \) |
| \( u_2 \) | For a uniform free volume charge density \( \rho_f(t) \) inside the slab of thickness \( s \), state the relation between \( E_x(x{=}s) \) and \( \rho_f(t) \) using Gauss's law. | \( \displaystyle E_x(x{=}s) = \frac{\rho_f(t)\, s}{2\varepsilon} \) |
| \( u_3 \) | Differentiate the expression from Step 2 with respect to time to obtain \( \partial E_x / \partial t \) at \( x = s \). | \( \displaystyle \left.\frac{\partial E_x}{\partial t}\right|_{x=s} = \frac{s}{2\varepsilon}\,\frac{\partial \rho_f}{\partial t} \) |
| \( u_4 \) | Substitute the expressions for \( E_x(x{=}s) \) and \( \partial E_x/\partial t \) from Steps 2 and 3 into the current density expression from Step 1. | \( \displaystyle \frac{i(t)}{A} = \sigma\,\frac{\rho_f\, s}{2\varepsilon} + \varepsilon\,\frac{s}{2\varepsilon}\,\frac{\partial \rho_f}{\partial t} \) |
| \( u_5 \) | Simplify the expression from Step 4 algebraically. | \( \displaystyle \frac{i(t)}{A} = \frac{\sigma\, s}{2\varepsilon}\,\rho_f + \frac{s}{2}\,\frac{\partial \rho_f}{\partial t} \) |
| \( u_6 \) | State the time-dependence of \( \rho_f(t) \) for initial value \( \rho_0 \) in a lossy dielectric with relaxation time \( \tau \). | \( \displaystyle \rho_f(t) = \rho_0\, e^{-t/\tau} \) |
| \( u_7 \) | Express the relaxation time \( \tau \) in terms of \( \varepsilon \) and \( \sigma \). | \( \displaystyle \tau = \frac{\varepsilon}{\sigma} \) |
| \( u_8 \) | Compute \( \partial \rho_f / \partial t \) from Step 6 using \( \tau \) from Step 7. | \( \displaystyle \frac{\partial \rho_f}{\partial t} = -\frac{\sigma}{\varepsilon}\,\rho_0\, e^{-t/\tau} \) |
| \( u_9 \) | Substitute \( \rho_f(t) \) and \( \partial \rho_f / \partial t \) from Steps 6 and 8 into the expression from Step 5. | \( \displaystyle \frac{i(t)}{A} = \frac{\sigma\, s}{2\varepsilon}\,\rho_0\, e^{-t/\tau} + \frac{s}{2}\!\left(-\frac{\sigma}{\varepsilon}\,\rho_0\, e^{-t/\tau}\right) \) |
| \( u_{10} \) | Algebraically combine the two terms from Step 9. | \( \displaystyle \frac{i(t)}{A} = 0 \) |
| \( u_{11} \) | State the resulting total current \( i(t) \) through the short circuit. | \( \displaystyle i(t) = 0 \) |
Table: An example reasoning flow. Each unit isolates a single reasoning step — retrieving a domain fact, applying a formula, or performing a local derivation — enabling fine-grained diagnosis of where model reasoning breaks down.
Setup. We isolate single-step competence via a unit execution test. For each unit index \( i \), we prompt the model with the original question \( Q \), the preceding units \( [u_1, \ldots, u_{i-1}] \), and the current sub-question \( u_i^q \), then verify whether the model produces the correct answer \( u_i^a \). We run 8 trials per unit and report mean accuracy across all questions whose reasoning flow includes unit \( i \) (excluding indices with fewer than five supporting instances).
Findings. Unit Execution diagnostics figures show that unit execution accuracy is consistently high, typically ~0.8-0.9 in the text subset, with a similar pattern and modest dips in the multimodal subset. This indicates that many end-to-end failures are not explained by an inability to execute individual steps once the correct sub-question is specified.
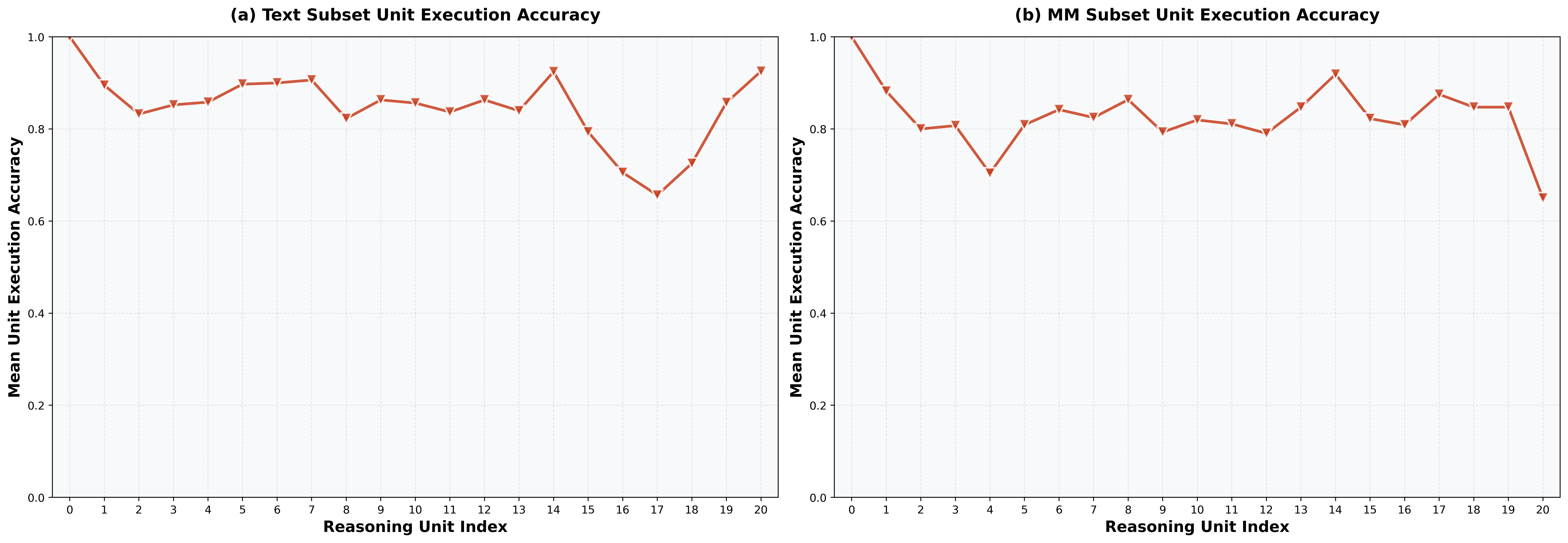
Figure: Unit Execution accuracy for text and multimodal subsets.
Setup. To examine long-horizon composition, we measure final-answer accuracy when progressively more of the reasoning flow is provided. For each unit index \( i \), we evaluate four prompting conditions: Reasoning Prefix (\( Q + [u_1, \ldots, u_i] \)), Reasoning Prefix (Questions Only) (\( Q + [u_1^q, \ldots, u_i^q] \)), Single-Unit Injection (\( Q + u_i \)), and Single-Unit Injection (Question Only) (\( Q + u_i^q \)). Each condition is sampled 8 times per question. We stratify by exact reasoning-flow length \( s \), restricting to buckets with at least five questions.
Findings. Across both modalities in the sample-level diagnostics, providing unit answers consistently outperforms providing only unit sub-questions. This gap indicates that the bottleneck is not merely identifying an appropriate decomposition, but reliably constructing correct intermediate states, i.e., producing the concrete intermediate values/expressions and preserving constraints as the derivation progresses. Notably, the performance gap is largest at mid-range unit indices. Early units tend to involve local setup and relatively direct manipulations, where the model can often proceed even without answer supervision; later units are increasingly dominated by the hardest long-flow instances and require a precise final consolidation step. In contrast, mid-chain units typically involve the most error-prone transformations. Providing the unit answers effectively "bridges" these difficult transitions, yielding the largest accuracy gains in the middle of the reasoning flow. Overall, this pattern suggests that current SOTA models are comparatively better at using correct intermediate results once provided, but remain brittle at deriving them and at faithfully maintaining state over long STEM derivations.
Figure: Sample-level diagnostics for the text subset. The red curve shows unit execution accuracy; other curves show final-answer accuracy under unit conditioning (Reasoning Prefix, Questions Only, Single-Unit Injection, and Question Only).
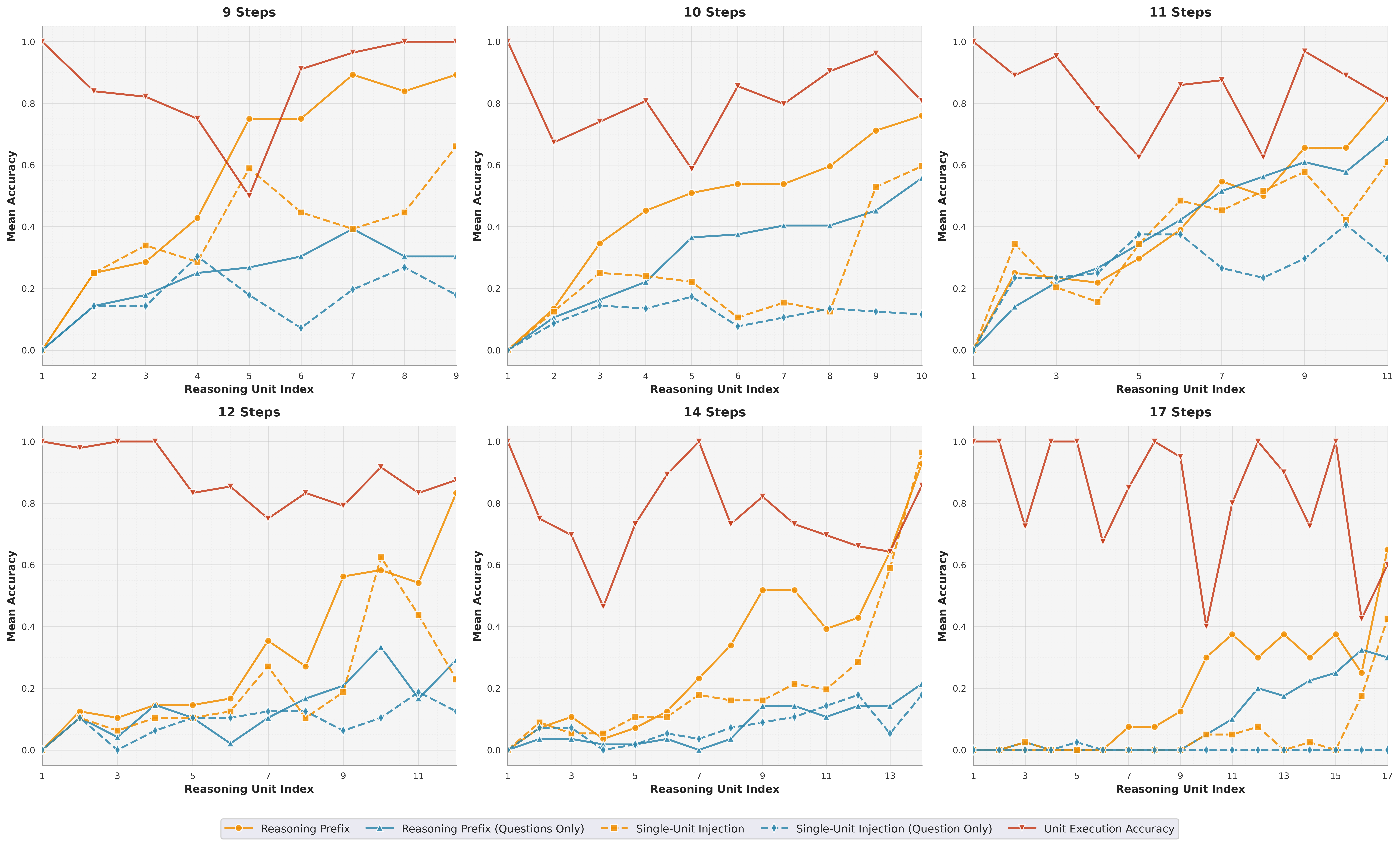
Figure: Sample-level diagnostics for the multimodal subset.
Setup. We test whether end-to-end success depends on a critical intermediate unit by injecting only a single unit \( u_i \) or only its sub-question \( u_i^q \), then evaluating whether the model can correctly answer the final question. We use the same 8-sample protocol as in Q2.
Findings. Across both subsets, Single-Unit Injection yields meaningful gains over the Questions Only variants, while Single-Unit Injection (Question Only) remains low across all diagnostics. This confirms that the missing information is often the unit answer, not merely the decomposition structure. Notably, injecting a single unit with its answer can be nearly as effective as providing a full reasoning prefix without answers, despite conditioning on substantially less context. This indicates that once a correct intermediate value is supplied, the model can proceed with downstream deductions almost as effectively as if guided by many preceding sub-questions. The limiting factor is not knowing what intermediate questions to ask, but reliably deriving the right intermediate answers and carrying them forward without drift.
Beyond end-to-end accuracy, we analyze how efficiently strong models solve CFE questions. We compare the distribution of reasoning-flow lengths between human-verified ground truth and model-generated solutions. Across both subsets, model responses are on average longer than the ground truth, indicating lower step efficiency. For the text subset, the mean response length is 12.20 versus a ground-truth mean of 10.73 (~14% longer); for the multimodal subset, the gap is larger: 13.86 versus 11.72 (~18% longer). This length inflation indicates that current models do not reliably allocate reasoning steps to efficient intermediate quantities.
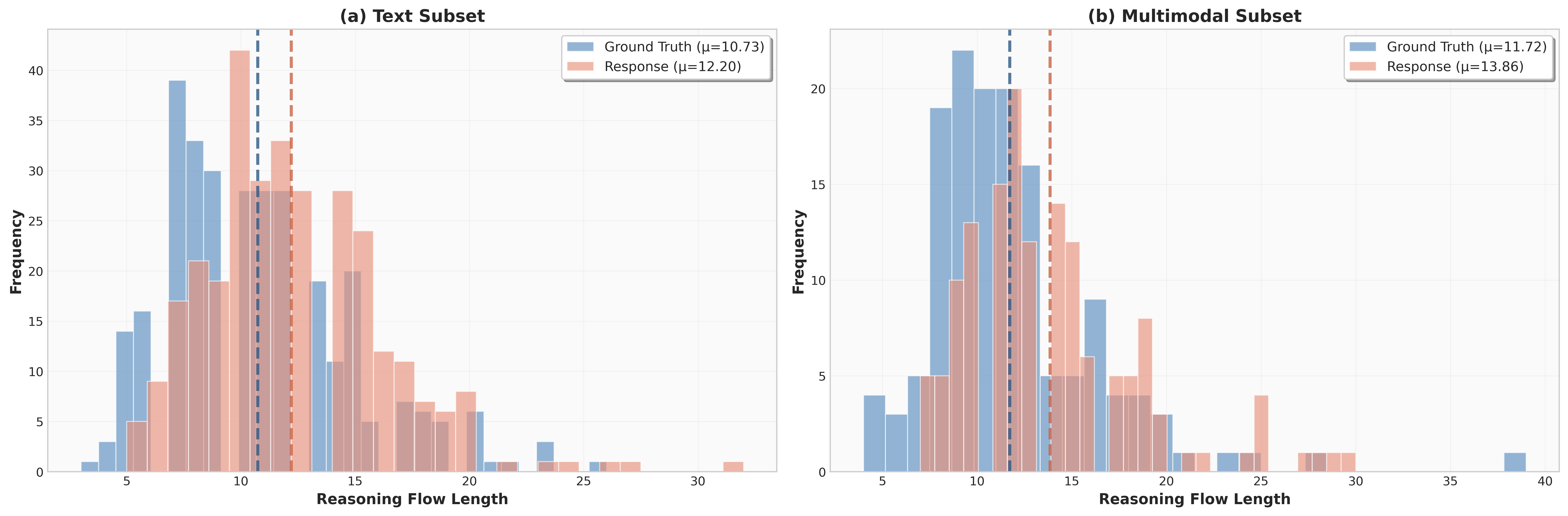
Figure: Reasoning-flow length distribution. Histograms show the frequency of questions at each length; dashed vertical lines indicate corresponding mean lengths.
| Statistic | Text Subset (n=305) | Multimodal Subset (n=144) | ||||
|---|---|---|---|---|---|---|
| Solved | Unsolved | Overall | Solved | Unsolved | Overall | |
| # Questions | 179 | 126 | 305 | 74 | 70 | 144 |
| GT len. (mean±std) | 10.60 ± 4.06 | 10.91 ± 4.07 | 10.73 ± 4.07 | 11.04 ± 3.39 | 12.44 ± 5.56 | 11.72 ± 4.63 |
| Resp. len. (mean±std) | 11.91 ± 3.62 | 12.62 ± 4.34 | 12.20 ± 3.95 | 13.19 ± 4.13 | 14.57 ± 5.05 | 13.86 ± 4.65 |
Table: Reasoning-flow length statistics by outcome. GT = ground-truth, Resp. = model response.
Our diagnostic experiments yield three main takeaways about why frontier models underperform on CFE, together with concrete implications for improving future SOTA systems.
(T1) Atomic competence is not the primary bottleneck. Under the unit-execution test (Q1), the model attains consistently high accuracy, indicating that many end-to-end failures are not driven by missing isolated facts or inability to perform a single local derivation once the correct sub-question is specified.
(T2) Correct intermediate answers are critical. Across both text and multimodal subsets, conditions that provide unit answers consistently outperform their corresponding "questions-only" variants, with the largest gains appearing at mid-range unit indices. This suggests that the primary bottleneck is not simply identifying a plausible reasoning flow, but reliably deriving and maintaining correct intermediate states throughout the solution process. Moreover, injecting a single unit together with its answer can be nearly as effective as providing a much longer reasoning prefix without answers. Taken together, these results indicate that the truly critical signal is often the correct intermediate answer itself: once a key intermediate value or statement is available, it can unlock downstream reasoning and substantially improve end-to-end success.
(T3) Current reasoning is inefficient. Models generate longer reasoning flows than the human ground truth in both subsets. This length inflation indicates lower reasoning efficiency, with extra steps creating more opportunities for intermediate drift and error accumulation.
Implications. A promising direction is stronger supervision of intermediate states, e.g., step-verified targets, constraint checking, and curricula that reward correct intermediate values rather than only final answers or fluent explanations. These findings also motivate hybrid systems that (i) compute or retrieve key intermediate values using stronger tools (e.g., symbolic solvers, verified calculators, or structured retrieval) and (ii) condition the model on these validated intermediates. More broadly, improving CFE performance will require more efficient reasoning; training objectives that penalize redundant steps and reward compact derivations are likely to improve both accuracy and efficiency.
@@misc{gao2026classroomfinalexaminstructortested,
title={Classroom Final Exam: An Instructor-Tested Reasoning Benchmark},
author={Chongyang Gao and Diji Yang and Shuyan Zhou and Xichen Yan and Luchuan Song and Shuo Li and Kezhen Chen},
year={2026},
eprint={2602.19517},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2602.19517},
}